Back Translation | 28/07/2021 - 20/08/2021
TL;DR : For the code checkout -> repository.
Adding to the data augmented with Syntax-Aware we further implement Back-Translation.
Back-translation is translating target language to source language and mixing both original source sentence and back-translated sentence to train a model. So the number of training data from source language to target language can be increased. This does both increasing the size for our dataset and adding noise to the data which inturn adds to the robustness of our translation model.
How is it done? Let us understand this with a flow in mind, starting with what will be our requirements.
- A dataset (in our case DBNQA - data.en and data.sparql)
- Translation model for English-to-SPARQL (en-sp model)
- Translation model for SPARQL-to-English (sp-en model)
- And a little patience :P (good things take time.)
as we work on requirements, We batch a subset of our data and translate English questions to respective SPARQL queries using the en-sp model.
English Questions (from data.en) -> SPARQL queries (translated from en-sp)
To obtain more data we have two options:
- We store these translations, and pass it to the sp-en model to translate them back to English questions
SPARQL queries (translated from en-sp) -> English Questions (translated from sp-en)
- We batch a subset of our data and translate SPARQL queries to respective English questions using the sp-en model.
SPARQL queries (from data.sparql) -> English Questions (translated from sp-en)
Here, 2 clearly has advantage over the quality of translations to that of 1, but lacks to add noise we expect in our data.
This required creating a training pipeline for both setups. Involves following steps:
- Getting the data
- Preprocessing data
- Defining translation model
- Setting up optimiser, loss function and evaluation metrics
The steps seemed to be quite quite straightforward but, while the at a certain step I encountered an issue very common with those related to large-scale datasets. Firstly for the preprocessing part,
- Reading the data from respective files
- Tokenization and building vocabulary
- Converting sentences to sequences, padding accordingly
Looking at these from a normal language-language translation problem, say English-German (most common) the default vocabulary size is roughly around 50K-60K which is quite scalable with today’s compute. On the other hand our dataset, builds up a vocabulary size of ~130K for the English lang. and ~250K for the SPARQL lang. Now, for traning the NMT the target sequences needed to be one-hot encoded in order to fit for the loss - categorical crossentropy.
- This simply was reshaping and creating a sparse vector for each word, from shape (1, N) -> (1, N, V)
- where N-length of sequence and V-size of language vocabulary.
Creating such a high indiced tensor consumed a large chunk of the memory each time causing either the system to crash or you sitting watching your screen get frozen for decades :P
One obvious initial solution that came to mind was to batch the sequences in order to lower the memory consumption, by encoding them right before they were given in to train the model. Tried out with various standard batching size (another hyperparameter to look out for) 128, 64, 32, and 16 all seem to make less or no difference by only delaying the inevitable crash by few moments. Batch size of 8 seemed to make move, but again on a later point during training (right during the 1st epoch) it again caused memory leaks and the story repeated.
After discussion with Tommaso and Anand we decided to try out subsampling the dataset in order to reduce the overall root of the problem - the huge size of vocabulary. Decided to sample 10% of the datapoints of the original dataset to test the idea. After obeserving and analyzing the dataset, every 300 examples had a overall same structure so decided to sample 10% (i.e 30) from each 300 questions. After sampling I had a scaled down version of the original dataset with ~89K pairs.
Finally, after few tweaks and fixes things were on track and the training was setup. I decided to drop the one-hot vectors that was root to the main problem, using the sequences with tokens and changed the loss accordingly, “categorical cross entropy” -> “sparse categorical crossentropy”.
The training went well, but the overall quality of translations was not acceptable. Possible reasons being using a smaller dataset, unappropriate hyperparameters and overall model architecture.
For instances,
| Actual | Predcited |
|---|---|
| Which place founded by party city is also the location fo katy grannan ? | Which place is the city is te also the location is the ? |
| What television show are distributed by national geographic society? | What is the show are are by is the show ? |
| What is the debut team of charlie fisher ? | What is the debut of of is the ? |
| What is the style of architecture of macfarland library ? | What is the style of place of whcih is ? |
| Did cris vaccaro manage a club of puerto rico national football team | Did is what place is the is the the team |
Clearly the tranlsation system did not generalize at all to the smaller(10%) subset of dataset we tried to use. A clear indication to the point that the number of occurences of a given named entity were way less than expected.
After brainstorming on the issue with mentors, we were sure that the subset selection was an inaapropriate approach choosen to sub sample. Instead suggested on trying and using a continous 10% section through the dataset for subsampling.
For initial expermenting purpose, first 10% i.e. 89640 pairs were sampled. The quality of translations drastically improved from what we had obtained before. For instance:
| Actual | Predicted |
|---|---|
| for which label did david holmes record his first album? | for which label did david holmes record his first album |
| give me all actors starring in movies directed by karim aïnouz | give me all actors starring in movies directed by karim aïnouz |
| give me all actors starring in movies directed by carlos de felitta | give me all actors starring in movies directed by raymond de felitta |
| give me all actors starring in movies directed by dee rees | give me all actors starring in movies directed by dee rees |
| for which label did diljit dosanjh record his first album? | for which label did diljit dosanjh record his first album |
| for which label did n. r. raghunanthan record his first album? | for which label did azam j raghunanthan record his first album |
| does bear whisperer have more episodes than absolutely fabulous? | does bear whisperer have more episodes than absolutely fabulous |
| does the adventures of clint and mac have more episodes than absolutely fabulous? | does the the of mac mac mac have more episodes than absolutely fabulous |
| give me all books by sterling e. lanier with more than 300 pages. | give me all books by nava macmel lanier with more than 300 pages |
| give me all books by yaşar kemal with more than 300 pages. | give me all books by yaşar kemal with more than 300 pages |
For a given sentence it generally has two name entities. For example: predicted=[does caught say goodbye have more episodes than absolutely fabulous], actual=[does never say goodbye have more episodes than absolutely fabulous?]
Here two main named entities in the actual data: “absolutely fabulous” and “never say goodbye” Predicted : “absolutely fabulous” and “caught day goodbye” In both cases, “absolutely famous” is correctly translated because it the base name entity during creation of examples from a template at a given point. Whereas “never say goodbye” occurs atmost 2 times in the entire set of given templates for above sentence which obviously is not enough for the model to generalize.
But this just might be a broader overview to the main issue ahead of us, a given named entity in a question/statement might be composed of more than a single word. Thus the level of generalization our model achieves all depends on the occurence of individual words throughout the dataset.
Considering the same example from before, “absolutely fabulous”, “never say goodbye” and “caught day goodbye” In our initial 10% dataset (i.e 89640) count of occurence for each word above for actual data
| word | count |
|---|---|
| absolutely | 300 |
| fabulous | 304 |
| never | 24 |
| caught | 4 |
| say | 122 |
| day | 23 |
| goodbye | 2 |
The number makes it even clear and evident on how the count affects the overall structure of entiities and there translations.
Thus the most evident approach currently in front of us was to train and experiment with higher percentages of the original dataset as our subsets. Keeping the memory limitations in mind and not to overload the instances decided to go with 10%, 15% and 20% of the initial datapoints for sampling the subset.
But for testing a common set was expected for fair evaluation amongst the models, thus the following splits were made (keep an) :
| Sampling% | Original size | Sampled size | Train% | Train size | Test% | Test size |
|---|---|---|---|---|---|---|
| 10% M10 | 894499 | 89449 | 85% | 76031 | 15% | 13418 (T1) |
| 15% M15 | 894499 | 134174 | 85% | 114047 | 15% | 20127 (T2) |
| 20% M20 | 894499 | 178899 | 85% | 157431 | 15% | 21468 (T3) |
To understand how words occured across the dataset we also tried visulizing the distribution of words. Plotting a direct word distribution would generate a clumsy and unintuitive graph which be of no help. Understanding the below plots:
- Distribution for 10% sampled set
- x axis has the number of occurences a particular word has over the given sampled set
- y axis has the number of words for a particular number of occurences
- For instance there are a total of 6 words which have a total of 58 occurences
- Note : the distribution is not continous becuase not all unique values are present for occurences thus it would have lead to a sparse graph
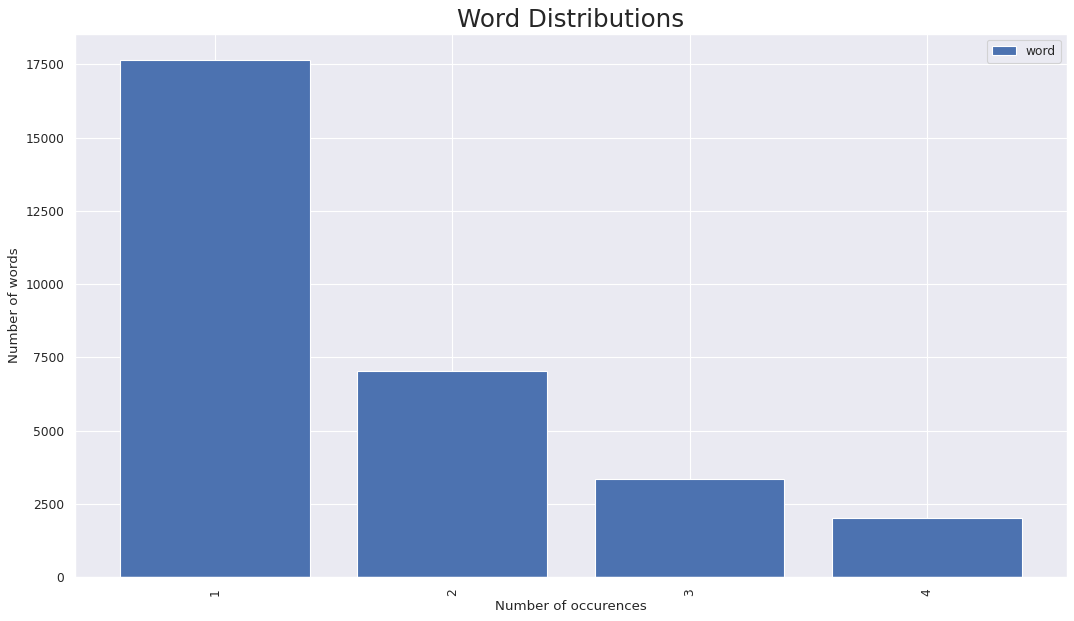
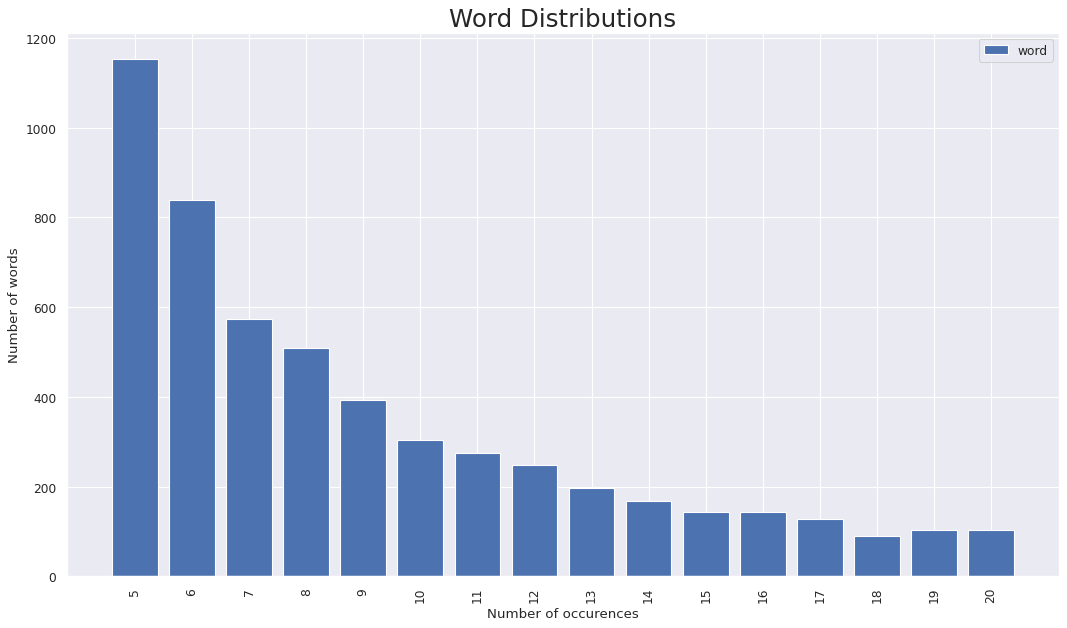
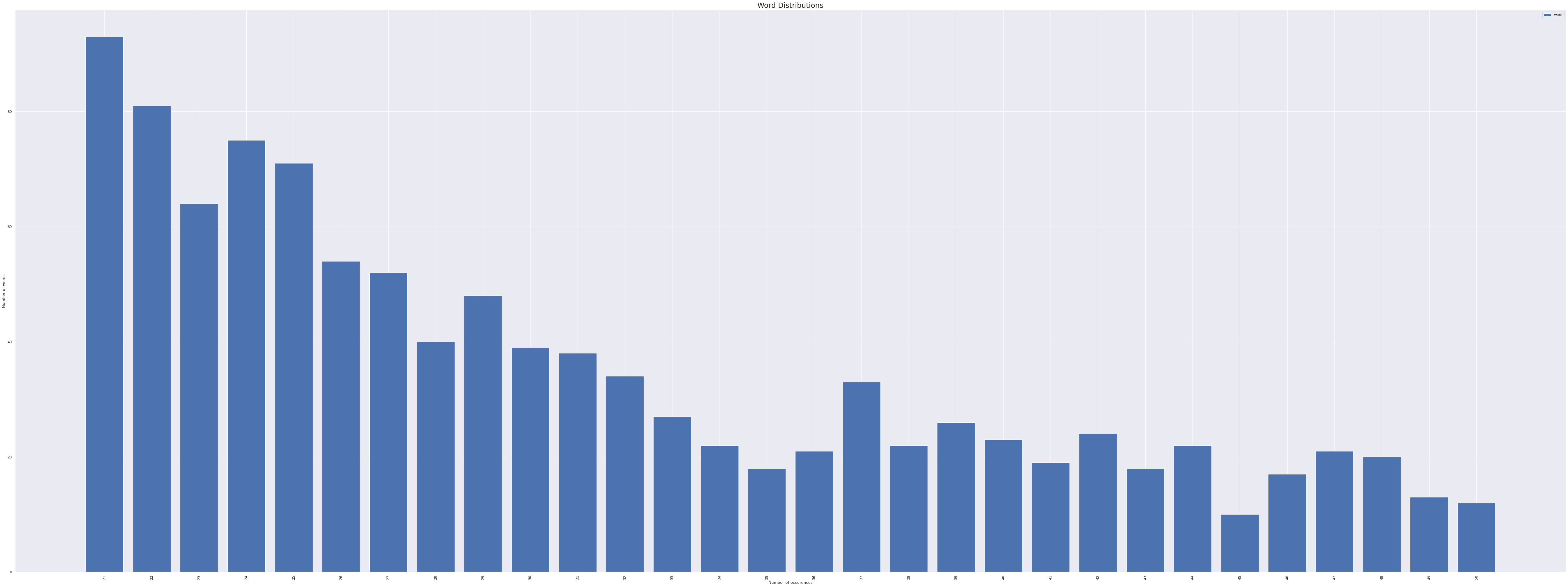
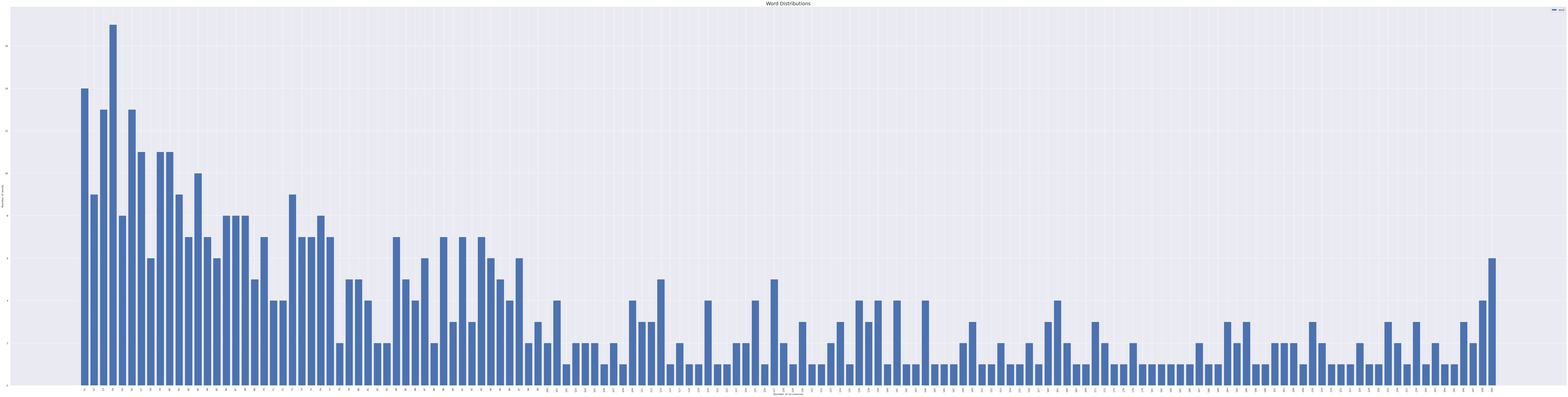
In the distribution we observe ~17.5K out of 36K unique words only appear once over the entire sampledset and are mostly the named entities or other words that significantly impact the semantic structure and meaning of sentence.
Observing over the terminating part of the plots we came across occurences of words in thousands, going upto 50084 occurence. These words were typically articles, stop words, puntuations like -> (a, the, of, is, are, from, for, what, who, does, etc.). These occurences do not directly hamper the performance or training of the model but create an initial imbalance to the dataset denying a normal distribution. Cutting down these words would be of no significant use rather would affect the performace. Thus increasing the initial would be appropriate. This left us with two possible approaches to the problem:
- Duplicating the examples a minimum number of times to ensure correct translations
- Creating new training data from the existing templates for given named entities
Coming back to models we mentioned earlier,
Each model was trained on the above mentioned samples and for the purpose of knowing the ‘How good the model translates’-metrics we calulated the BLEU (Bilingual Evaluation Understudy) Score on the same set of examples here T1 (refer above table for more)
| Model | bleu |
|---|---|
| 10% M10 | 59.78651 |
| 15% M15 | 55.34126 |
| 20% M20 | 74.99421 |
The M20 performed very well, but it has high chances a few test samples were already seen by it during its training. Thus to find a minimum number (a threshold) for occurences plotted the predicted sentences.
Following are the plots presented with inference on M20 model.
Sentence : ‘does the gösebek flow into into lake’
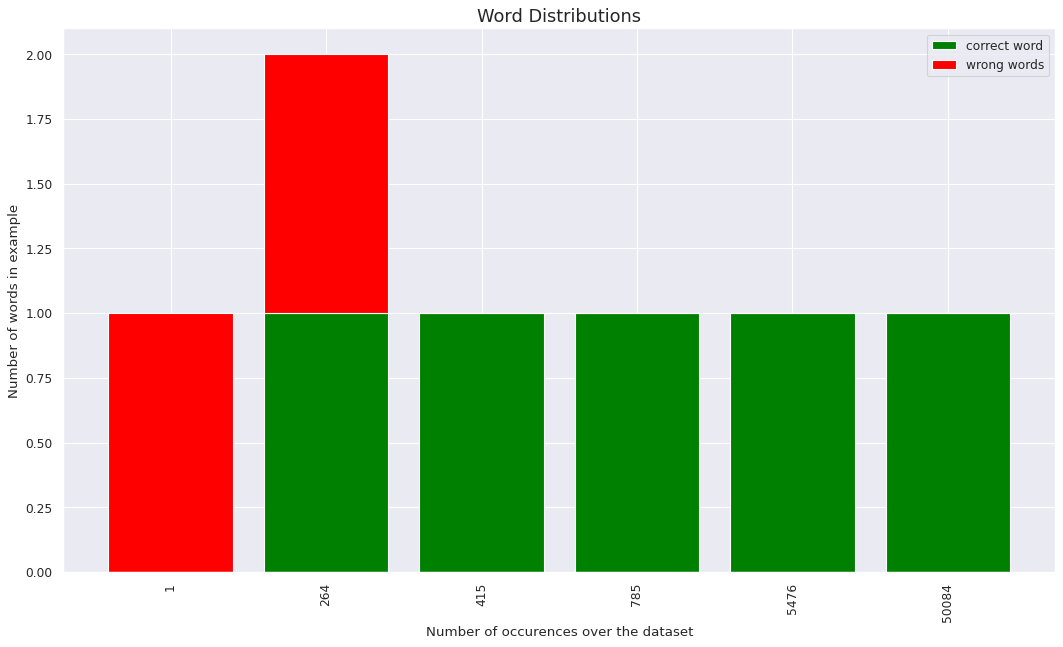
Sentence : ‘what is the place of birth of the meyrick pringle kwong akmar’
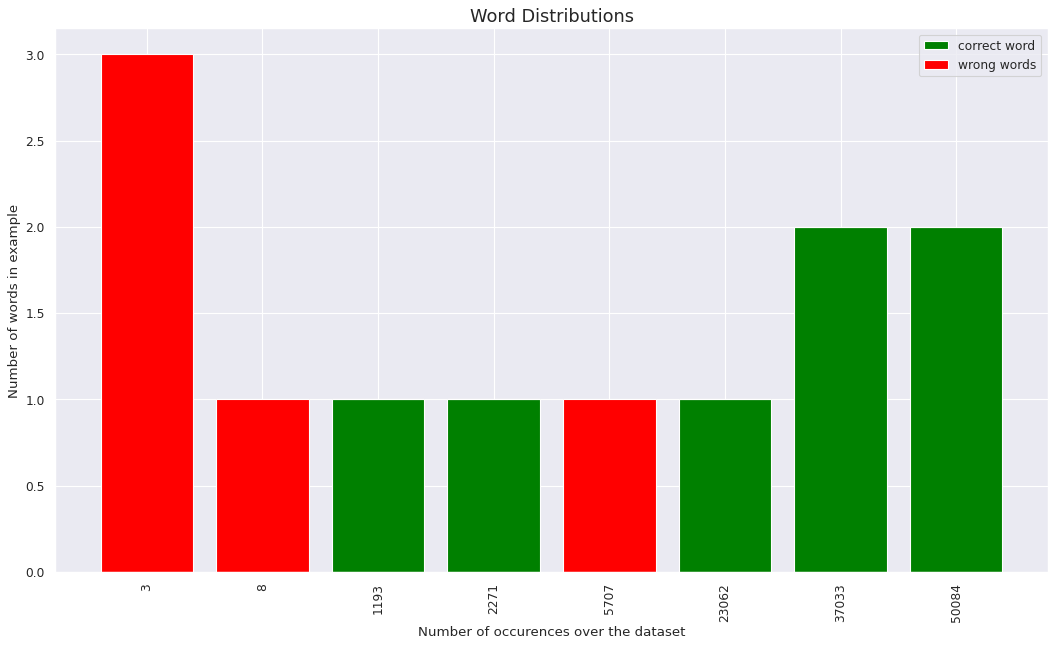
Sentence : “list the awards received of the person whose child is jen sagan”
Plotting individual sentences proved to be more or less of no help in finding out a significant value to the threshold desired. Thus decided to have a collective plot for better understanding. Taking only the perfectly translated pairs are correct and rest everything as wrong.
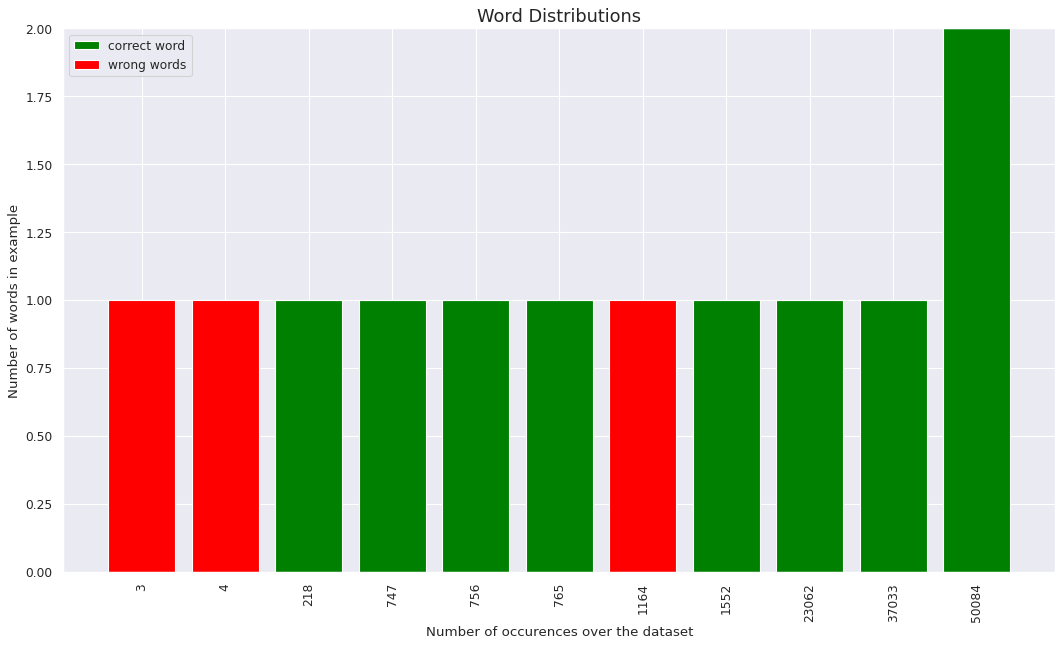
Following are distributions for a random sample of 200 pairs.
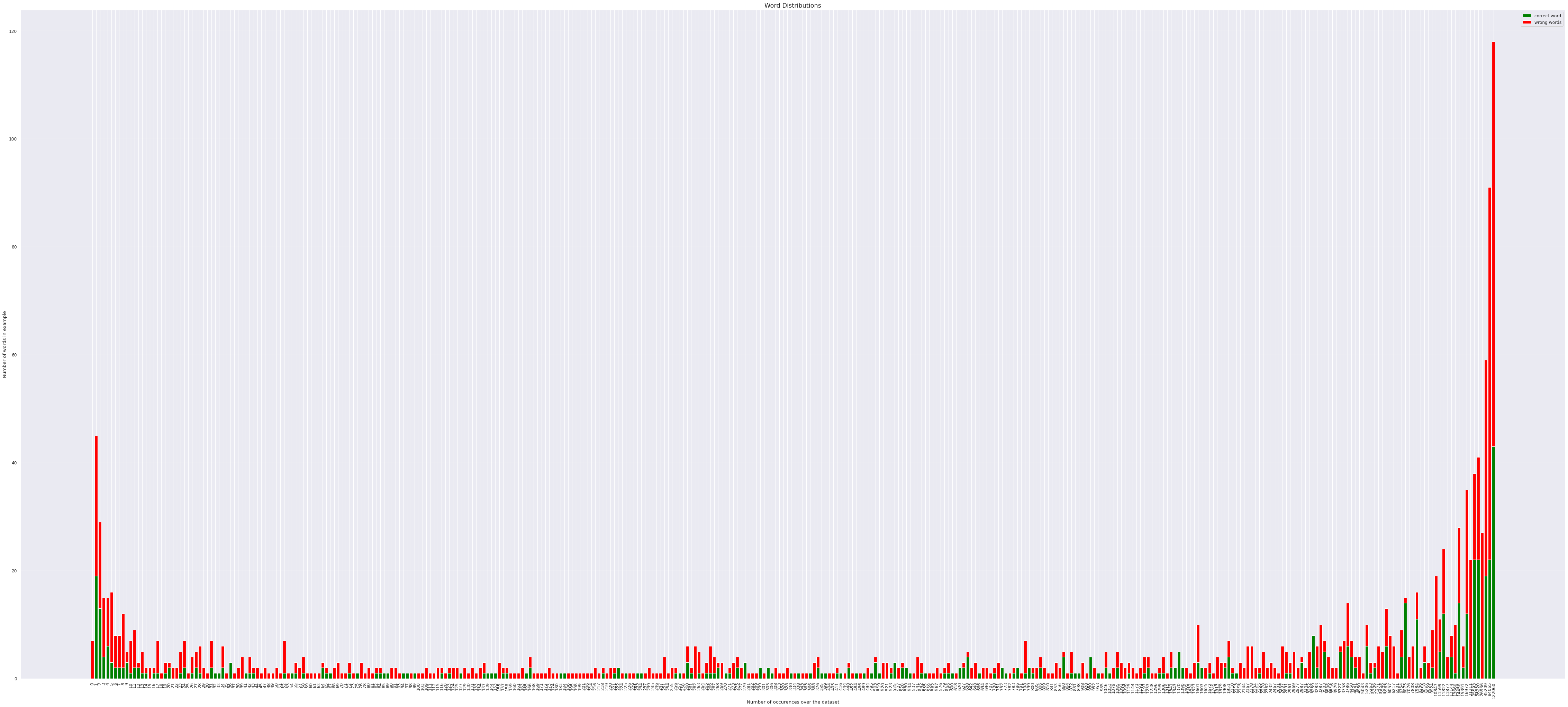
- BLEU score for the particular batch of 200 sample pairs was 0.78375813
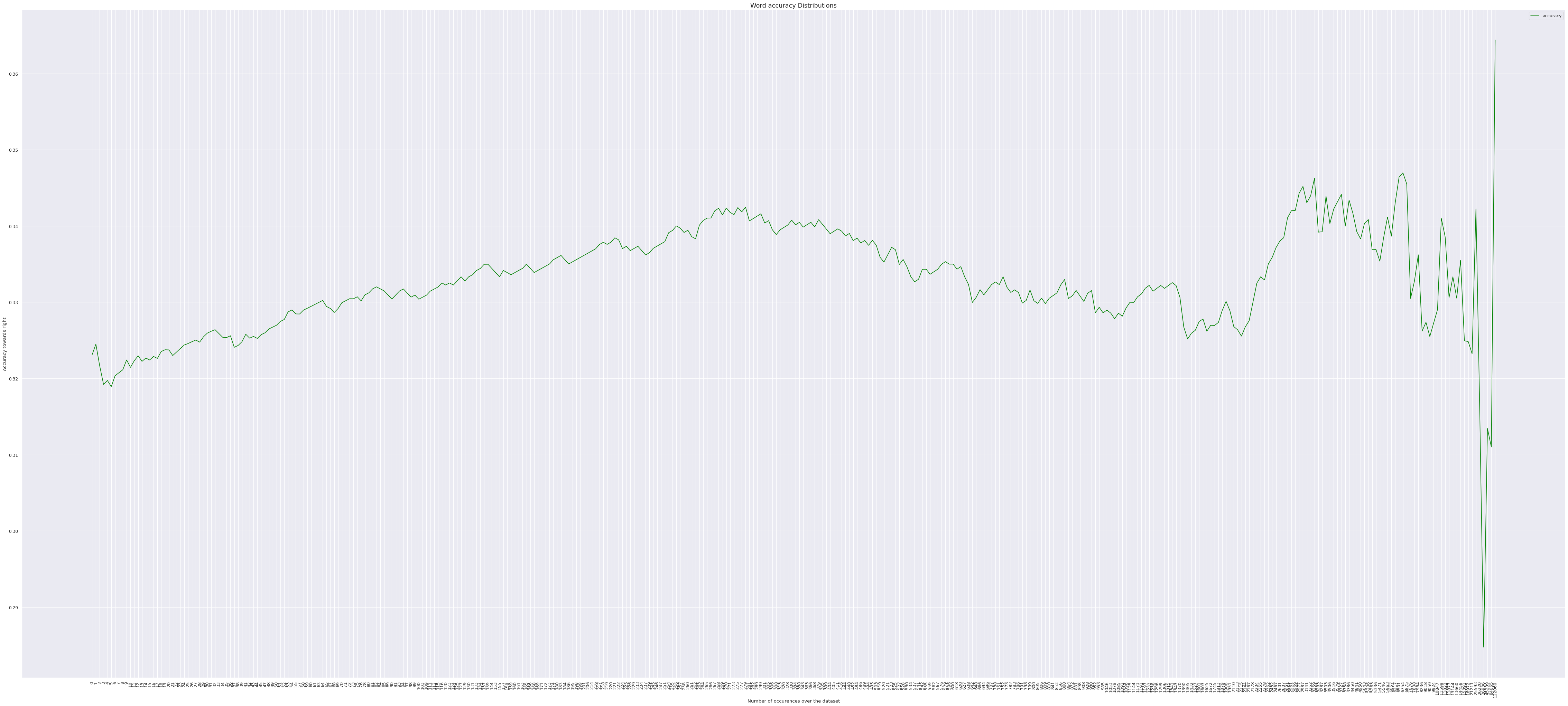
- Following graphs are presented with a critria which takes word level translation into consideration to justify the high BLEU score.
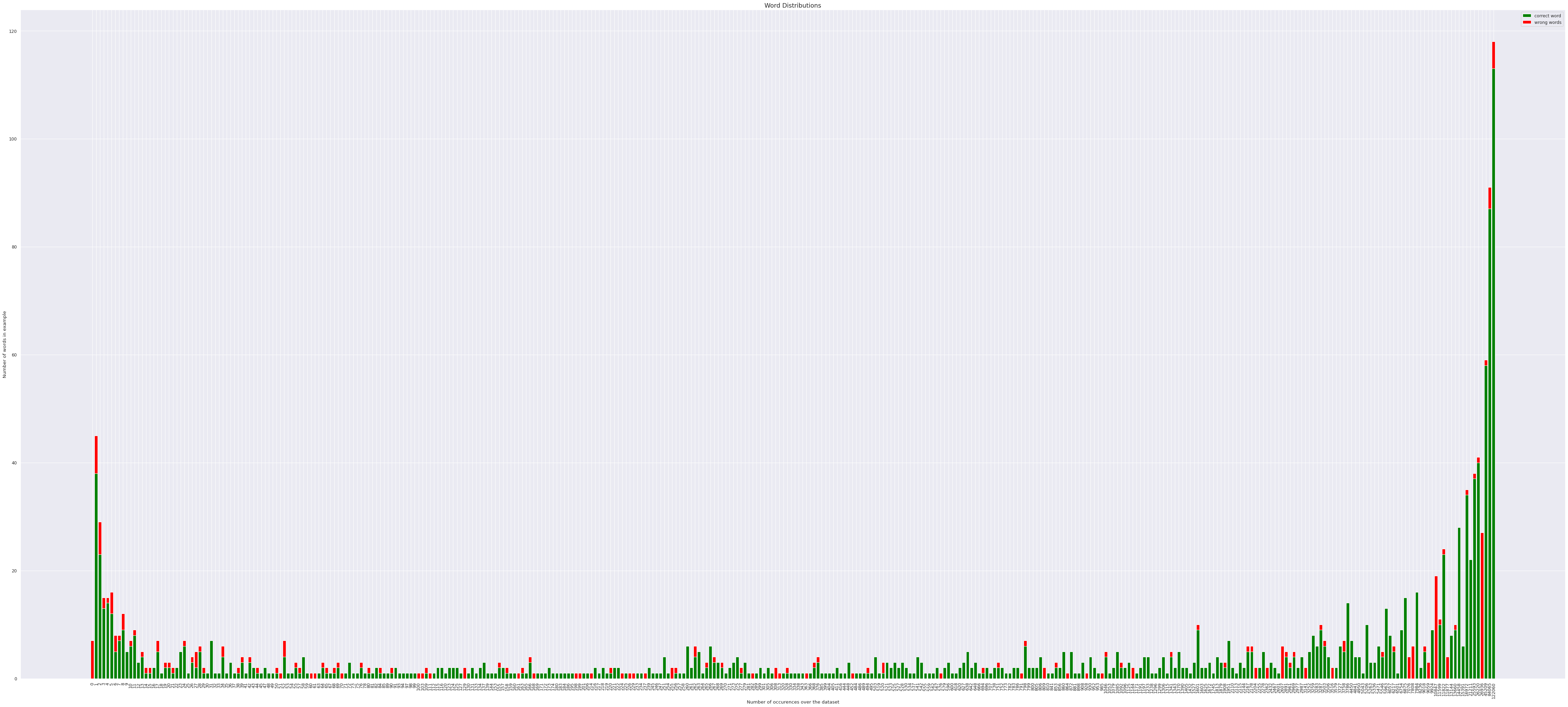
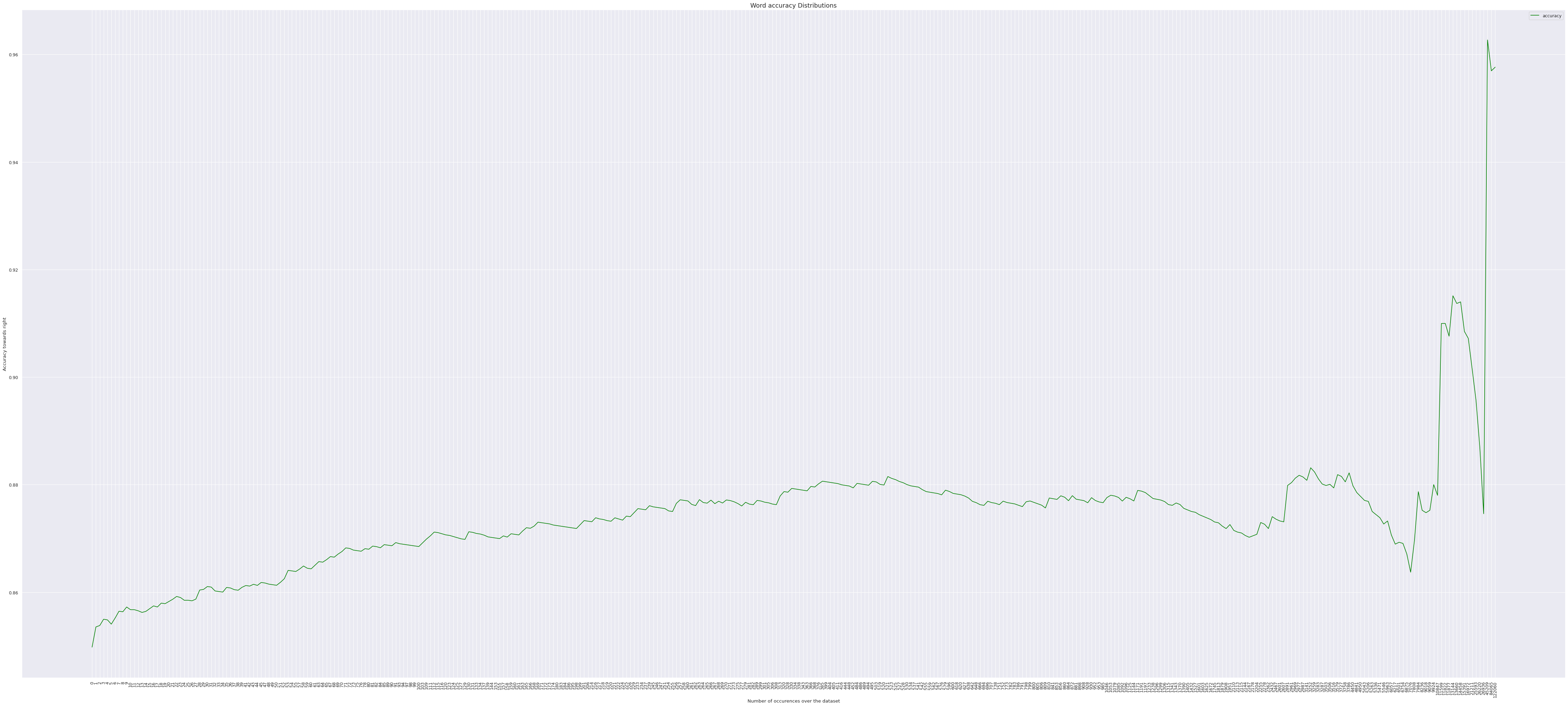
The second plot is both cases, gives in a lot of insight on how the occurence of a unique word has impact on being correctly translated by the model.
- We observe a gradual increase over the value, indicating that a higher order of word occurence does prove to have more chances of being translated correctly but the number does not seem to have a significant variance over the distribution given only between 85% - 95% for the later plotted.
- Increasing the sample size adds no major diference to the plots above, with slight variations of +-5% on the lower boundary.
- Thus we can conclude for threshold as,
| Accuracy | Min. instances of occurence |
|---|---|
| 80-85% | 3-8 |
check the code for Back-Translation for creating parallel corpus of training data, and the entire work at neural-qa