Project overview
My project “Neural QA Model for DBpedia” has an end term goal of helping normal users (non-dev) explore the huge knowledge graphs at DBpedia by putting in questions in thier native laguage (English as of now). Ahh, but is answering a question such a big deal for a project? Kindoff yes.
Accessing these huge knowledge graph is only possible using querys - specificlly SPARQL queries, now for a normal person writing a SPARQL query is too much to expect. Thus we come bridging the gap - Translating your Native language question to SPARQL query. Yes, a slightly inlined towards machine translation project.
Also this is the 4th year for the project to be selected in Google Summer of Code, the project has evolved very well over the period of time. Taking it further we intend to bring it few steps closer to perfect ;) That being said, I’ll be using two major datasets DBNQA and Lc-QuAD both as training and testing respectively.
Timeline
For the first 3 weeks (07/06/2021 - 27/06/2021) I shall be implementing “Syntax Aware Augmentation” as a resort of making the model robust to noise and extending the current state of dataset.
Syntax-Aware Augmentation | 07/06/2021 - 27/06/2021
TL;DR : For the code checkout -> repository.
This technique is being incorporated with the main motive of increasing the robustness and accuracy of NSpM, along with extending the existing DBNQA dataset via Augmentation.
Primarily focusing on three sub techniques:
- Dropout : Words in sentence are dropped
- Blanking : Words in sentence are randomly replaced with a special placeholder token <BLANK>
- Replacement : Words in sentence are selected and replaced with one word which has a similar unigram word frequency over the dataset.
Rather than using word frequency or random selection we have used Dependency tree depth as a hueristic clue. It is well known that the meaning of a sentenceis actually determined by only a few of importantwords. Thus modifying those syntactically and semantically more important words may alter the sentence more radically.We abstain from choosing too important words. To meet such requirements, we need to find a heuristic clue to measure how much important a word is, and then determine selecting probability to alter the corresponding word for data augmentation.
Given a sentence s=w1,w2,…,wn of length n, we first calculate a probability qi based on di,the depth of word wi, by
qi = 1 - (1 / 2d i - 1)
Q = {q i}
P(S) = Softmax(Q(S))
P(S) = {p1, p2, .. pn}
Dependency parsing
is the task of analyzing the syntactic dependency structure of a given input sentence S. The output of a depen-dency parser is a dependency tree where the words of the input sentence are connected by typed dependency relations.
Transition based approach to dependency parsing is motivated by a stack-based approach called shift-reduce parsing originally developed for analyzing programming languages. This classic approach is simple and elegant, employing a context-free grammar, a stack, and a list of tokens to be parsed. Whereas, Graph-based approaches to dependency parsing search through the space of possibletrees for a given sentence for a tree (or trees) that maximize some score. Thesemethods encode the search space as directed graphs and employ methods drawnfrom graph theory to search the space for optimal solutions
Sentences are majorly classified under projective and non-projective, in which the dependency lines do not intersect at any given section for the before one. Experimented for both transition-based and graph-based dependency trees with an endterm moto for probabilities for word selection. Came to conclusion for using Neural transition based parsing tree as it has obvious advantage over the parsing accuracy and execution time.
The parsing gives us an output tree, which we use to find the depths and relative probabilites of words present in the sentence. A glance at the output tree for the sentence.
Little into code,
The above presented theory builds up a brief understanding of the overall motive.
For performing the intended operations, I have written 3 scripts, namely :
- syntax_aware.py - has all the implementations for necessary actions round the project
- utility.py - some helper functions.
- augment.py - takes in all the functions, and executes it at a single place.
We start by taking in the data files, data.en - data file containing english questions and data.sparql - data file containing respective SPARQL queries, which are our input to the overall program. A list for sentences present is created for respective files, and then is molded to form pairs. Inorder to create augmented data, we randomly select language pairs created initially (the user chooses the number of samples to be used). Following operaions are functional under the utility script.
We initally sample 100 sentence pairs, and the process goes as:
Example for single sentence
“What is the nationality of the guy gavriel kay which is also the sovereign state of the françois langelier?”
Which is the passed to the dependency tree (function from syntax_aware) which internally parses the sentences and creates a tree and then into a graph essentially to provide us with depths for each word for the given sentence.
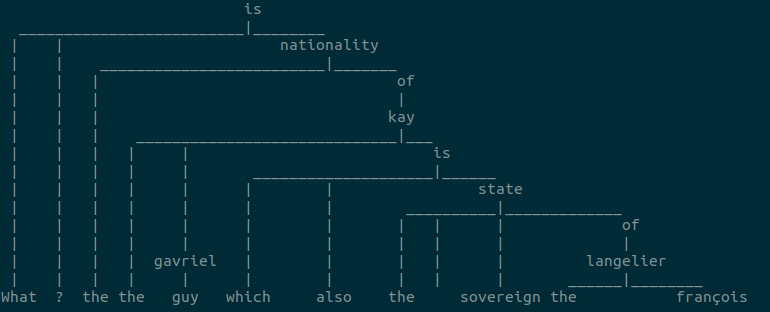
By getting the depth from the tree :
[‘What’, ‘is’, ‘the’, ‘nationality’, ‘of’, ‘danyon’, ‘loader’, ‘which’, ‘also’, ‘the’, ‘sovereign’, ‘state’, ‘waitomo’, ‘caves’, ‘hotel’]
[2, 1, 3, 2, 3, 5, 4, 2, 2, 3, 3, 2, 4, 0, 1]
Using depths found we internally calculate final probabilites(using the formula mentioned above) and return them:
[‘What’, ‘is’, ‘the’, ‘nationality’, ‘of’, ‘danyon’, ‘loader’, ‘which’, ‘also’, ‘the’, ‘sovereign’, ‘state’, ‘waitomo’, ‘caves’, ‘hotel’]
[0.87144306, 0.7, 0.95085018, 0.87144306, 0.95085018, 1.00603215, 0.98809904, 0.87144306, 0.87144306, 0.95085018,0.95085018, 0.87144306, 0.98809904, 0.7]
Based on the length of the sentence we decide on the number of augmentations to be performed, accordingly selecting words with maximum probability “dayon” -> 1.00603215 & “loader” -> 0.98809904 (here, 2) and performing operations.
Replacement
We test two distinct approaches :
- Synonym replacemment (syntax_aware.replacement):
- We use a list of synonyms obtained from news data over the internet, as we obtain the indices of the words we need to augment we get the lexicon for the entire sentence and perform acordingly - synonyms.
- Uses a helper functions : get_syn_lex which returns the lexicon for the entire sentence
- Running a set of 100 samples for Augmentation take time : 2.70-3.10 sec (may vary from devices)
- Similar word replacement (syntax_aware.word2vec_replacement)
- Trained a word embedding (Word2Vec) on the Text8 corpus for obtaining the word vector for the selected words.
- Made a search in the embeddings’ dimensions (100-d for ours) around a fixed space with relative similar vectors.
- Found the most similar words by comparing the cosine similarity for the vectors for words, with 1 being high and 0.5 realtively low. Selected the word with highest cosine sim. value.
- Running a set of 100 samples for Augmentation take time : 9.30-15.00 sec (may vary from devices)
for “loader”
embeddings : [ 2.87076589e-02 6.55337214e-01 1.83130503e-01 6.36373907e-02 1.72789529e-01 … 2.46303618e-01 8.24105918e-01]
top 5 words :
(‘loader’, 0.9999998807907104), (‘operating’, 0.6293714642524719), (‘booting’, 0.6258991360664368), (‘firmware’, 0.6177793145179749), (‘device’, 0.6041673421859741)
Following the process, we create new pair of data.
Via synonym replacement
| Original Questions | Augmented Questions |
|---|---|
| Which training center of phyllis birkby has also alumni named roger hilsman ? | Which training center of phyllis birkby has also graduates named roger hilsman ? |
| Name the university located in urban area and has affiliations with aicte? | Name the université located in urban area and has affiliations with aicte ? |
| Which maintainer of riverside drive is also the city of usa final 1967 ? | Which maintainer of riverside drive is also the twon of usa final 1967 ? |
| Name some basketball players who have played for bc brno? | Name some basketball players who have played for bc brno? |
In the last example we observe, actually nothing has been replaced. Which helps us take the technique with a pinch of salt that not all sentences will be replaced and augmented due the fact the not all sentences might have any common words whose synonyms are worth replacing them.
Dropout
- Pretty straight forward (syntax_aware.dropout), using the same probabilities we drop words from the sentence. Considering the length of the sentence (threshold 13 words) we drop words accordingly.
- Threshold refers to the length of sentence taken into consideration, if the length < threshold we only drop single word with highest probability.
- Running a set of 100 samples for Augmentation take time : 0.60-0.90 sec (may vary from devices)
| Original Questions | Augmented Questions |
|---|---|
| does superstar hair challenge have more episodes than absolutely fabulous? | does superstar hair challenge have more episodes absolutely fabulous? |
| does the new son amores series have more episodes than the old one? | does new son amores series have more episodes the old one? |
| Give me the count of newspaper whose language is greek language and headquartered at syria ? | Give me count of newspaper whose language is greek language and at syria ? |
| What is the life stance of the ethnic groups related to brazilian american ? | What is the life stance of ethnic groups related to brazilian american ? |
| Give me list of people who were the first to climb a peak in the takayama? | Give list of people who were first to climb a peak in the takayama? |
Note how the 2nd, and 3rd example had to offer 13(or more)words, we dropped two words on the go.
overall,
| Input | data files (data.en and data.sparql) |
| output | data files (repalced/dropped.en & .sparql) |
check the code for Syntax-aware augmentation and the entire work at neural-qa thus to concluding with, augmentation techniques are basically used to lend a hand to help train a machine learning model better given small size datasets.